











什么是"VTA-LDM"?
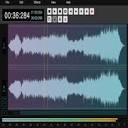
VTA-LDM是一款由Tencent AI Lab开发的视频到音频生成模型,旨在根据视频输入生成语义和时间上对齐的音频内容。该模型基于先进的文本到视频生成技术,为研究人员提供了视频到音频生成范式的洞见。
"VTA-LDM"有哪些功能?
1. 生成与视频内容语义和时间上对齐的音频内容。
2. 支持自定义超参数,以适应个人需求。
3. 提供脚本,可将生成的音频内容与原始视频合并。
产品特点:
1. 支持多种模型,包括VTA_LDM、VTA_LDM+IB/LB/CAVP/VIVIT等。
2. 提供了预训练模型和文本输入功能,增强了生成音频的灵活性和多样性。
3. 基于先进的视频处理技术,生成的音频内容与视频内容完美对齐。
应用场景:
1. 视频编辑领域:用于为视频内容生成高质量的音频背景音乐或配音。
2. 娱乐产业:用于音频内容的生成和处理,例如语音合成、音频特效等。
"VTA-LDM"如何使用?
1. 安装Python依赖,并下载模型检查点。
2. 将视频片段放入数据目录。
3. 运行提供的推理脚本,生成音频内容。
4. 使用提供的脚本,将生成的音频内容与原始视频合并。
常见问题:
暂无常见问题。
数据统计
相关导航






暂无评论...






























三维导航 - 最大的综合性网址导航网站,提供AI导航、自媒体导航、设计导航等数十个垂直导航。我们致力于发现优质产品工具,帮助用户快速找到所需信息。我们能为您提供全面的导航服务。通过我们的网站,您可以轻松地找到您需要的资源,节省时间和精力。欢迎访问3wdh.com,开始您的导航之旅!
 鲁ICP备18016225号-1
鲁ICP备18016225号-1